
Super resolution with Deep Learning: SRGAN
The Super Resolution GAN (SRGAN) is a deep learning algorithm whose objective is to improve the quality of an image. It belongs to the family of GANs (Generative Adversarial Networks). In this article, we will first discuss the different existing deep learning algorithms for image processing and we will then see more precisely what a GAN is. Finally, we will discuss the specificity of SRGAN. To analyze images, we often use a Convolutional Neural Network (CNN). It is a deep learning algorithm that allows convolutions to extract features from an image. This type of algorithm is used for image classification or image recognition. However, it does not allow to generate or modify an image, and for that we should use GANs.
- Functioning, applications and variants of GANs -
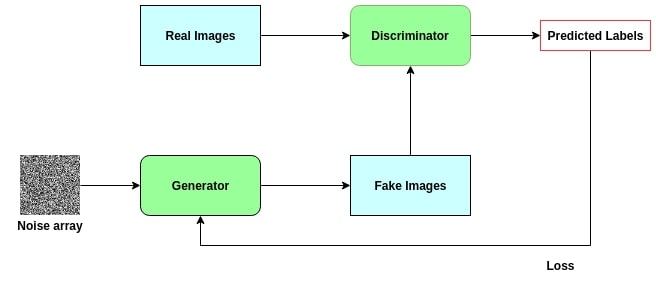
A GAN is an algorithm that transforms or generates images. If we refer to its definition, a GAN is composed of two neural networks competing against each other. They are adversaries. However, we could rather say that the second network is the trainer of the first one, let's see why. The two networks that make up a GAN are the generator and the discriminator: The generator will take as input an image (or a random vector) and will provide as output the transformed image (or the generated image). The role of the discriminator will be to judge the quality of that transformation (or generation). For that, the discriminator will have, at its disposal, images coming from the generator as well as real images. He will then have to determine if the generated images are real or fake (artificial). As you will have understood it, the discriminator is nothing else than a binary classification algorithm applied to images, it is a CNN (Convolutional Neural Network). During the first iteration, it will be very easy for the discriminator to determine the nature of the images provided (real or artificial). The objective of the generator is to improve during the training to make the task of the discriminator more and more difficult. There is still an element to be specified. How does the generator improve with each iteration? The discriminator has a double role. It must not only determine the nature of the images but also communicate to the generator how it has succeeded in its mission, so that the generator can improve. It is for that reason that we can consider that the discriminator is not the opponent of the generator but rather its trainer. The following is a diagram summarizing the functioning of a GAN:
There are many variations of GANs, but the idea behind each one of them is the same as the one presented above. Each variant addresses a specific use case. We can start by mentioning SRGAN, the algorithm that we will see in more detail below. We can also mention the styleGAN algorithm, which was developed by NVIDIA in 2018 and is available as open-source since 2019. This algorithm generates very realistic human faces. Compared to a classic GAN, the generator is much more complex. Here is the type of results we can get:

- SRGAN: How the algorithm works -
Let's turn to SRGAN, which is a variant of GANs. Instead of using two neural networks, it uses three. This algorithm is specifically designed to do image super-resolution (or image depixelation). We start with the generator, the discriminator, and we add a third network: the VGG19 network. The latter is a CNN that won a deep learning competition aimed at classifying images from the ImageNet database (several million images). That network is already trained and is very (very) efficient. We are going to use that network to make sure that the image coming from the generator conforms to the image we want to obtain. This is an additional way of ensuring the quality of the generation (in addition to the discriminator). Now, to start the implementation, we will need a database of low resolution images and their corresponding high resolution ones. We will provide the generator with the low resolution images and it will produce, in output, images of higher resolution. We will then give the discriminator the real images and the generated ones so that it can train to differentiate them. We will also provide them to the VGG19 network. The network will return the feature maps of the real and generated images. A feature map is a 2D matrix of neurons located after the activation layer of a filter. It is what a neural network learns from an image. We will compare these feature maps to get an idea of the quality of the generation. It makes more sense to do a comparison between the feature maps than to apply the MSE (mean squared error) between the two sets of images directly. The original SRGAN paper comes back on this point: [1609.04802] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network.This explains the good performance of an SRGAN compared to a regular image depixing GAN. Let's explain further more through a concrete example: Let's say that we have images of size (64*64) that we want to transform into size (256*256). During the training phase, we have the same images in both (256*256) and (64*64) versions. We provide the images of size (64*64), as input, to the generator and we get the output. After that, we send the real images and the generated ones (256*256) to the discriminator and the VGG. We reiterate that process to improve the performance of the generator. Finally, we test our algorithm by providing the generator with new images of size (64*64). If it is correctly trained, it will provide a better quality image.