
Super resolution with Deep Learning: SRGAN
The Super Resolution GAN (SRGAN) is a deep learning algorithm whose objective is to improve the quality of an image. It belongs to the family of GANs (Generative Adversarial Networks).
In this article, we will first discuss the background of image super-resolution and the different deep learning algorithms used for image processing. We will then see more precisely what a GAN is and how it works, before diving into the specific architecture of SRGAN. Finally, we will explore its applications, limitations, and future directions.
- Why image super-resolution matters -
In today’s digital world, we are surrounded by images - from social media photos and surveillance videos to medical scans and satellite imagery. However, many of these images suffer from poor resolution due to compression, noise, or hardware limitations. Super-resolution aims to reconstruct high-quality images from low-resolution inputs.
Traditional approaches to image enhancement included interpolation methods like bilinear or bicubic interpolation. While fast, these methods often produce blurry and unrealistic results because they cannot restore lost fine details. Deep learning, particularly CNNs and GANs, revolutionized the field by learning from vast datasets to hallucinate missing details, producing sharper and more natural-looking images.
- GANs and their functioning -
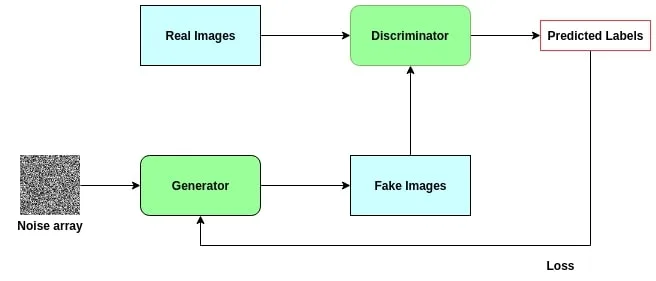
A GAN is an algorithm capable of generating or transforming images. It was introduced by Ian Goodfellow in 2014 and has since transformed AI research.
GANs consist of two main components:
- Generator: Creates new images from random noise or low-resolution inputs. Its goal is to produce outputs that are indistinguishable from real images.
- Discriminator: Judges whether an image is real (from the dataset) or fake (produced by the generator). It acts as a binary classifier.
These two networks are trained simultaneously in a minimax game. The generator improves by learning to fool the discriminator, while the discriminator improves by learning to detect fakes. Over time, the generator becomes highly skilled at producing realistic images.
There are many GAN variants, each optimized for a specific use case. For instance, StyleGAN by NVIDIA generates hyper-realistic human faces. Conditional GANs (cGANs) generate images based on labels or attributes. CycleGANs perform style transfer, converting paintings to photos or horses to zebras. SRGAN is the variant specialized for super-resolution.
- SRGAN: How the algorithm works -
Introduced in 2017 by Ledig et al., SRGAN was the first framework capable of generating photo-realistic images for 4x upscaling tasks. Its innovation lies in combining adversarial learning with perceptual loss functions derived from pretrained networks.
The architecture includes three main components:
1. Generator
The generator is a deep residual network (ResNet) with 16 residual blocks followed by two sub-pixel convolution layers for upsampling. Each residual block contains two 3×3 convolutional layers, batch normalization, and Parametric ReLU (PReLU) activations, connected by a skip connection that adds the block's input directly to its output. These skip connections serve two purposes: they prevent gradient vanishing in deep networks, and they allow the generator to focus on learning the residual (the missing detail) rather than reconstructing the entire image from scratch.
The upsampling at the end is done with sub-pixel convolution (also called pixel shuffle), rather than traditional transposed convolutions. Instead of inserting zeros between pixels, sub-pixel convolution learns to rearrange channels into spatial dimensions - producing higher-resolution outputs with far fewer checkerboard artifacts than deconvolution-based approaches. The final layer uses a tanh activation to clip pixel values into the [−1, 1] range.
2. Discriminator
The discriminator is a deep CNN classifier inspired by VGGNet, progressively increasing in depth and decreasing in spatial resolution. It uses 8 convolutional layers with 3×3 kernels, batch normalization (except in the first layer), and Leaky ReLU activations. The spatial features are flattened and passed through two dense layers before a final sigmoid activation outputs a probability: is this image real or generated?
During training, the discriminator receives both real high-resolution images from the dataset and fake super-resolved images from the generator. It learns to assign high scores to real images and low scores to generated ones. This adversarial pressure forces the generator to produce outputs that are perceptually indistinguishable from real photographs - textures, edges, and fine details that pixel-wise loss functions would never encourage.
3. VGG19 and perceptual loss
SRGAN's most impactful innovation is replacing pixel-wise MSE loss with a perceptual loss derived from VGG19, a convolutional network pretrained on ImageNet for image classification. The key insight: if two images look similar to a human, their internal feature representations in a deep network should also be similar - even if their pixel values differ.
Rather than comparing output and ground truth pixel by pixel, SRGAN passes both images through VGG19 and measures the L2 distance between their feature maps at a specific intermediate layer (typically the layer just before the 5th max-pooling operation). This captures high-level structural similarity - shapes, textures, object edges - rather than low-level pixel accuracy. The practical effect is dramatic: a model trained with MSE loss produces smooth, plausible-but-blurry images optimized for PSNR; a model trained with perceptual loss produces sharper, more textured images that score higher in human perception tests, even if their PSNR is slightly lower.
- Loss functions in SRGAN -
To understand why SRGAN's loss design was a breakthrough, you first need to understand why standard MSE loss fails at super-resolution.
When you train a network to minimize the mean squared error between its output and the ground truth image, you are asking it to find the average of all plausible high-resolution images that could correspond to the given low-resolution input. Because many slightly different textures could all be valid reconstructions, the network learns to produce a smooth, hedged answer - a blurry image that is never wrong in a catastrophic sense, but also never sharp. High PSNR, low perceptual quality.
SRGAN replaces this with a compound loss that trades some pixel accuracy for visual realism:
- Content loss (perceptual): The L2 distance between VGG19 feature maps of the generated and ground-truth images. This measures structural and textural similarity in a high-level feature space rather than raw pixel space. It allows the network to reconstruct textures that are perceptually correct even if they don't match the reference pixel-for-pixel.
- Adversarial loss: The log probability that the discriminator classifies the generated image as real. Minimizing this loss pushes the generator toward the manifold of natural-looking high-resolution images, adding micro-textures and edge sharpness that content loss alone cannot induce.
- Total loss: A weighted sum of content loss and adversarial loss. The weight controls the trade-off: more adversarial weight → sharper but potentially more artifact-prone; more content weight → smoother but blurrier. The original SRGAN paper used a ratio of 10⁻³ for the adversarial component.
This compound design is what makes SRGAN outputs look subjectively better than any prior method, even when objective metrics like PSNR rank them lower. Human observers consistently prefer SRGAN results over higher-PSNR but blurrier alternatives - a finding confirmed by the Mean Opinion Score (MOS) study in the original paper.
- Training SRGAN -
Training a GAN is notoriously more complex than training a standard supervised network, because two models must improve simultaneously without one outpacing the other. SRGAN follows a careful two-phase strategy:
- Dataset preparation: High-resolution images (e.g., from DIV2K or ImageNet subsets) are used as ground truth. Low-resolution inputs are generated on-the-fly by bicubic downsampling with a factor of ×4. This paired setup means the model is always trained on images where the "correct" answer is known.
- Generator pretraining (MSE phase): Before adversarial training begins, the generator is pretrained for several thousand iterations using only pixel-wise MSE loss. This gives it a reasonable starting point - images that are blurry but structurally correct. Starting adversarial training from random weights often leads to mode collapse, where the generator gets stuck producing one type of output regardless of input.
- Adversarial training (GAN phase): The generator and discriminator are trained in alternating steps. First the discriminator is updated on a batch of real and generated images; then the generator is updated using the compound loss (content + adversarial). The learning rate for both networks is set to 10⁻⁴ and decayed at regular intervals. The original SRGAN paper trained for 10⁵ update steps at each scale.
- Evaluation: Performance is measured with PSNR and SSIM for objective fidelity, and with Mean Opinion Scores (MOS) from human raters for perceptual quality. Because SRGAN optimizes for perception rather than pixel accuracy, it often scores slightly lower on PSNR than simpler methods while scoring significantly higher in MOS - demonstrating why a single metric is never sufficient to evaluate super-resolution models.
- Applications of SRGAN -
- Medical imaging: MRI and CT scans are inherently resolution-limited by acquisition time, patient motion, and hardware constraints. SRGAN-derived methods can enhance scan resolution in post-processing, revealing finer anatomical structures without increasing radiation dose or scan duration. Research has shown particular promise in cardiac MRI and brain MRI, where subtle texture differences can indicate pathology.
- Satellite and aerial imagery: Commercial satellites produce imagery at resolutions of 30–50 cm per pixel; smaller operators may only achieve 1–5 meters. Super-resolution allows analysts to extract finer details from lower-cost imagery for applications in crop monitoring, urban planning, disaster response, and military reconnaissance.
- Forensics and surveillance: Security cameras are often too far from their subjects to capture identifying details at native resolution. SRGAN-based tools can recover readable license plates or recognizable facial features from footage that would otherwise be inadmissible or uninformative. Real-ESRGAN is particularly effective here because it handles the JPEG compression artifacts common in CCTV recordings.
- Entertainment and media restoration: Streaming platforms and game studios use super-resolution to upscale older content to 4K. NVIDIA's DLSS (Deep Learning Super Sampling) applies similar principles in real-time gaming, rendering at lower internal resolutions and upscaling to display resolution, boosting frame rates without sacrificing visual quality. Classic films and anime series have been commercially remastered using these techniques.
- E-commerce and product photography: Catalogue images submitted by vendors are often compressed and low-quality. Super-resolution pipelines can automatically enhance product images before display, improving perceived quality and, according to A/B testing, measurably increasing conversion rates.
- Limitations and improvements -
Although powerful, SRGAN has some limitations:
- Training is unstable and requires careful tuning.
- Artifacts like ringing or checkerboard patterns may appear.
- Performance depends heavily on training data quality.
These issues led to improvements such as:
- ESRGAN (2018): Enhanced SRGAN replaced batch normalization with Residual-in-Residual Dense Blocks (RRDB), which stack multiple dense connections without BN. This removed BN artifacts and produced sharper, more realistic textures. ESRGAN won the PIRM 2018 challenge on perceptual super-resolution.
- Real-ESRGAN (2021): Extended ESRGAN to handle real-world degradation pipelines - including JPEG compression, noise, blur, and downsampling artifacts combined. Instead of clean bicubic downscaling as input, it simulates the messy conditions found in real photos, making it far more robust for practical deployment.
- Benchmark comparison: SRGAN and its successors -
The table below compares key super-resolution methods on the standard Set5 benchmark at ×4 upscaling. Higher PSNR and SSIM indicate better pixel-level fidelity; perceptual quality is assessed separately.
| Method | Scale | PSNR (Set5) | SSIM (Set5) | Notes |
|---|---|---|---|---|
| Bicubic | ×4 | 28.42 dB | 0.810 | Fast interpolation - blurry results |
| SRCNN | ×4 | 30.48 dB | 0.863 | First CNN approach (Dong et al., 2014) |
| SRGAN | ×4 | 29.40 dB | 0.827 | Lower PSNR than SRCNN but best perceptual score (MOS study) |
| ESRGAN | ×4 | 31.81 dB | 0.894 | Sharper textures, no BN artifacts - PIRM 2018 winner |
| Real-ESRGAN | ×4 | - | - | Handles real-world noise/JPEG/blur; no clean-data PSNR |
Note: SRGAN intentionally sacrifices PSNR for perceptual realism. Human evaluators consistently prefer SRGAN outputs over higher-PSNR but blurrier alternatives.
- Code example (PyTorch) -
import torch
import torch.nn as nn
# Residual block for SRGAN
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, 3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.prelu = nn.PReLU()
self.conv2 = nn.Conv2d(channels, channels, 3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
return x + residual
This snippet shows how residual blocks are implemented in the generator. Stacking multiple such blocks allows SRGAN to model complex image textures.
- The future of SRGAN and super-resolution -
SRGAN opened a research trajectory that has accelerated every year since its publication. Several directions now define the frontier of the field:
Diffusion-based super-resolution. Models like StableSR (2023) and DiffBIR adapt the denoising diffusion process - originally developed for text-to-image generation - to the super-resolution task. Diffusion models iteratively refine an image from noise, guided by the low-resolution input at each step. This produces outputs with richer, more coherent textures than GAN-based methods, though at the cost of slower inference (many denoising steps vs. a single generator forward pass).
Video super-resolution. Applying frame-by-frame super-resolution produces flickering artifacts because each frame is processed independently. Models like EDVR and BasicVSR++ extend the approach to video by explicitly modeling temporal alignment between frames using deformable convolutions and optical flow. This ensures that textures remain consistent across time, enabling real-time 4K upscaling of streaming content.
Reference-based super-resolution. When a high-resolution reference image of the same subject is available (e.g., a photo taken moments earlier at full resolution), the model can transfer specific textures and details from the reference to the super-resolved output - producing results far beyond what blind upscaling alone can achieve.
On-device and real-time inference. Apple's Metal Performance Shaders, NVIDIA's DLSS 3, and AMD's FSR incorporate super-resolution directly into GPUs and mobile chips. These implementations run in milliseconds, making real-time 4K upscaling from 1080p a standard feature in modern games and video players. The underlying networks are typically distilled and quantized versions of ESRGAN-family architectures.
Ultimately, SRGAN and its successors are paving the way for a future where any low-quality image can be transformed into a sharp, realistic representation - breaking the barriers of hardware limitations and unlocking new possibilities in science, media, and communication.
- References -
- Ledig, C. et al. (2017). "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network." CVPR 2017. arXiv:1609.04802.
- Wang, X. et al. (2018). "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks." ECCV 2018 Workshops. arXiv:1809.00219.
- Wang, X. et al. (2021). "Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data." ICCV 2021 Workshops. arXiv:2107.10833.
- Dong, C. et al. (2014). "Learning a Deep Convolutional Network for Image Super-Resolution." ECCV 2014.
Comments