Retrieval-Augmented Generation (RAG): From First Principles to Production Systems
Large Language Models (LLMs) look impressive when we see them write code, summarize articles, or answer complex questions. However, once we try to deploy them inside a real organization, a fundamental limitation becomes obvious: they do not actually have access to the information that matters to your business.
They do not know your internal procedures, your contracts, your data warehouse, your documentation, nor your latest reports. More importantly, they cannot verify whether the information they generate is correct.
This gap between impressive demos and real production requirements is precisely what Retrieval-Augmented Generation (RAG) was designed to solve. RAG is not a model. It is a system architecture that transforms a general-purpose language model into a domain-aware and knowledge-grounded assistant.
In this article, we will build RAG step by step, from first principles to production-grade systems. You will understand not only how RAG works, but also how to design it properly, how to evaluate it, and how to avoid the most common failure modes.
1. Why pure language models fail in real applications
To understand why RAG is necessary, we must first be precise about what an LLM actually learns. A language model is trained to estimate the probability of the next token given the previous tokens:
From a statistical perspective, the model is optimized to maximize likelihood. There is no objective function related to truth, correctness, factual consistency, or source verification.
As a result, when an LLM does not know an answer, it does not remain silent. It generates the most plausible continuation. This behavior is often referred to as hallucination.
In real systems, hallucinations are not just embarrassing. They create operational risk. In regulated industries such as finance, insurance, healthcare, or legal services, a single incorrect answer can lead to financial loss or compliance violations.
Another structural limitation is that LLMs are trained on static corpora. Once training is finished, their internal knowledge becomes frozen. Any information created after that moment is invisible to the model unless you retrain it.
Finally, even when the model has seen similar information during training, it cannot cite or verify sources. The knowledge is stored implicitly inside billions of parameters. This makes auditing and governance extremely difficult.
RAG directly addresses these three limitations:
- it allows models to access external and up-to-date information,
- it grounds generation in retrieved evidence,
- it enables traceability to original documents.
2. What Retrieval-Augmented Generation really is
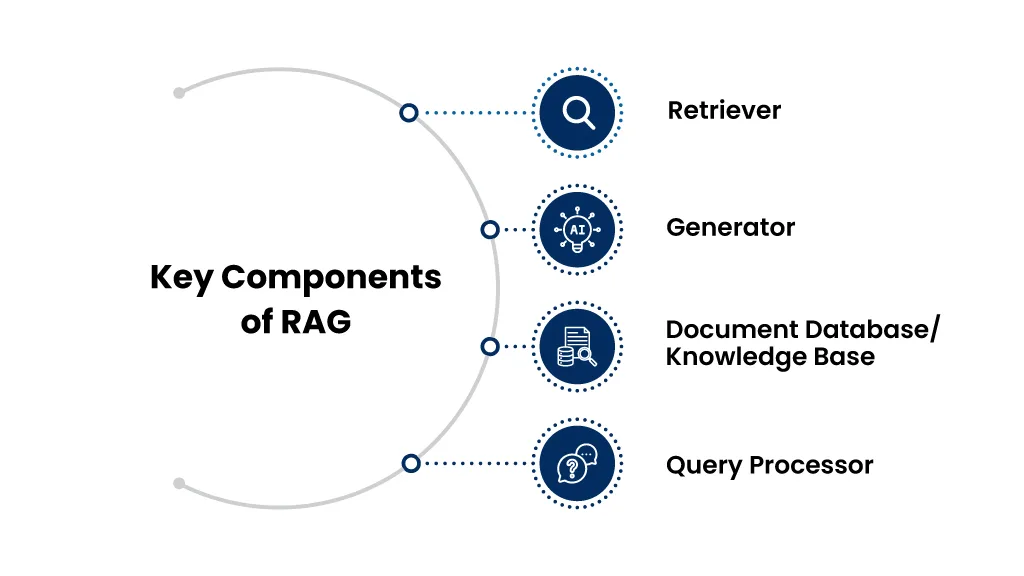
At a high level, a RAG system decomposes the question-answering problem into two distinct stages:
- retrieve potentially relevant information,
- generate an answer conditioned on that information.
The retriever operates on a knowledge store. The generator is the language model.
This separation is essential. It allows each component to evolve independently:
- you can update your data without touching the model,
- you can improve retrieval quality without changing generation,
- you can swap the LLM without rebuilding the data layer.
From a system design perspective, RAG introduces a non-parametric memory alongside the parametric memory of the neural network. The neural network is responsible for reasoning and language. The data layer is responsible for storage and retrieval.
This design is conceptually similar to classical information systems: the LLM becomes a reasoning engine on top of a knowledge infrastructure.
3. From lexical retrieval to semantic retrieval
Before neural embeddings, information retrieval relied almost exclusively on lexical matching. Systems indexed documents using inverted indexes and ranked them using heuristics such as TF-IDF or BM25.
These approaches remain extremely efficient and robust. However, they are fundamentally based on surface form. Two texts that express the same idea using different words may not be matched at all.
Semantic retrieval addresses this limitation by mapping texts into a continuous vector space. An embedding model implements a function:
The geometry of this space is constructed so that semantically related texts are located close to each other.
This allows the system to retrieve documents that are conceptually aligned with a query even if no keywords overlap.
In RAG systems, semantic retrieval enables users to ask natural language questions without needing to know the exact terminology used in the documents.
4. Designing a realistic ingestion and embedding pipeline

The ingestion pipeline is one of the most underestimated parts of RAG. Most failures in production are caused by poor data preparation rather than poor models.
A robust ingestion pipeline usually consists of the following stages:
- document loading and format normalization,
- text extraction and cleaning,
- structural segmentation,
- chunking,
- embedding computation,
- storage of vectors and metadata.
In practice, loading documents is far from trivial. PDFs, scanned documents, HTML pages and Word files all require different parsing strategies. Poor extraction quality directly propagates into poor retrieval.
Once text is extracted, normalization becomes essential. This includes:
- removal of boilerplate content,
- deduplication,
- handling of headers and footers,
- language detection.
Only after this preparation should chunking and embedding be applied.
A minimal example using a sentence transformer and FAISS:
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
documents = [
"Retrieval-Augmented Generation connects LLMs to external data.",
"Vector databases enable fast similarity search over embeddings."
]
embeddings = model.encode(documents, normalize_embeddings=True)
embeddings = np.asarray(embeddings).astype("float32")
index = faiss.IndexFlatIP(embeddings.shape[1])
index.add(embeddings)
In real systems, you must always persist the following metadata together with each vector:
- document identifier,
- chunk identifier,
- source file or URL,
- position within the document,
- optional access control information.
Without metadata, traceability and debugging become nearly impossible.
5. Chunking is a modeling decision, not a preprocessing detail
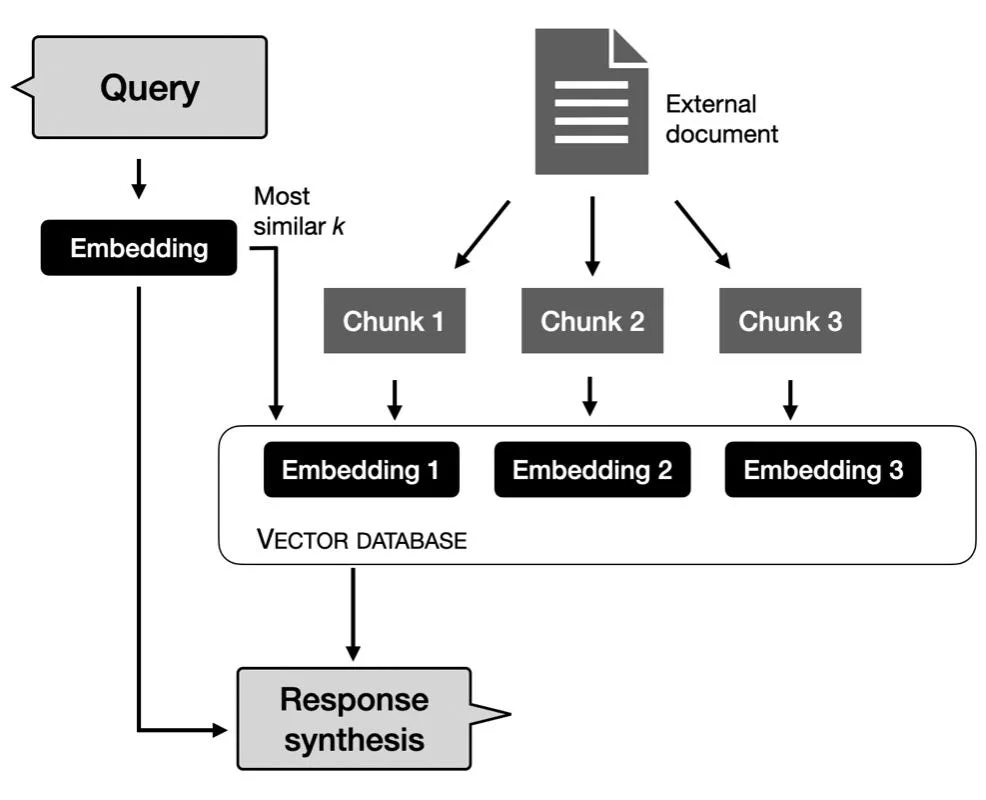
Chunking determines what information is visible to the retriever and to the generator. It therefore directly influences recall, precision and hallucination rates.
If chunks are too small, the retriever may retrieve fragments that lack sufficient context. If chunks are too large, the semantic signal becomes diluted and similarity search becomes less accurate.
A commonly used baseline strategy is fixed-size token windows with overlap. For example:
- 400 tokens per chunk,
- 80 tokens overlap.
However, this strategy ignores document structure. In many domains such as legal contracts, insurance policies or technical standards, semantic boundaries align with sections and headings.
Semantic chunking attempts to preserve these boundaries by using:
- headings,
- layout structure,
- topic segmentation models.
In practice, hybrid approaches are often used: structural segmentation followed by size-constrained windows.
6. Dense, sparse and hybrid retrieval strategies
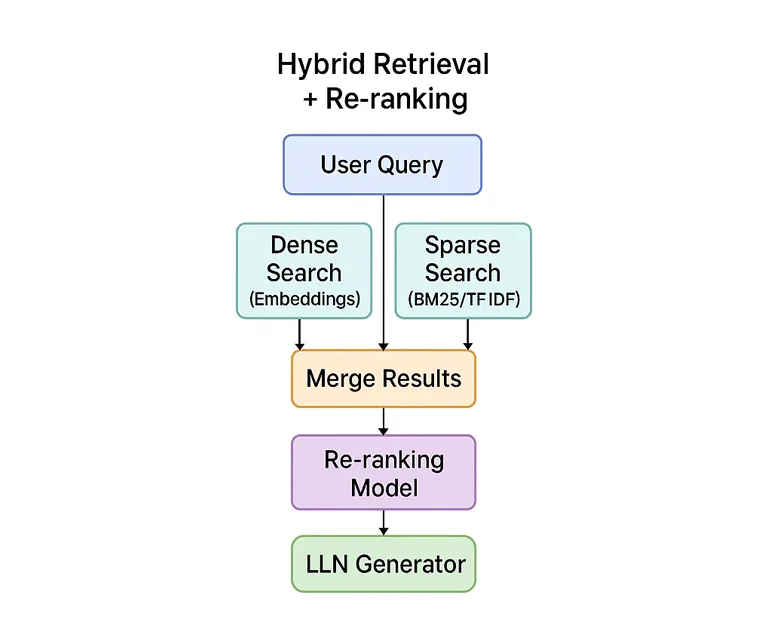
Dense retrieval relies on embeddings and vector similarity. It performs well for conceptual and descriptive queries.
Sparse retrieval relies on lexical matching. It remains extremely important for:
- identifiers,
- codes,
- article numbers,
- exact terminology.
Hybrid retrieval combines both approaches. A common pattern is:
- retrieve candidates using vector search,
- retrieve candidates using BM25,
- merge the results,
- rerank them.
Hybrid retrieval significantly improves robustness, especially for technical and regulatory content.
7. Reranking: where most quality gains come from
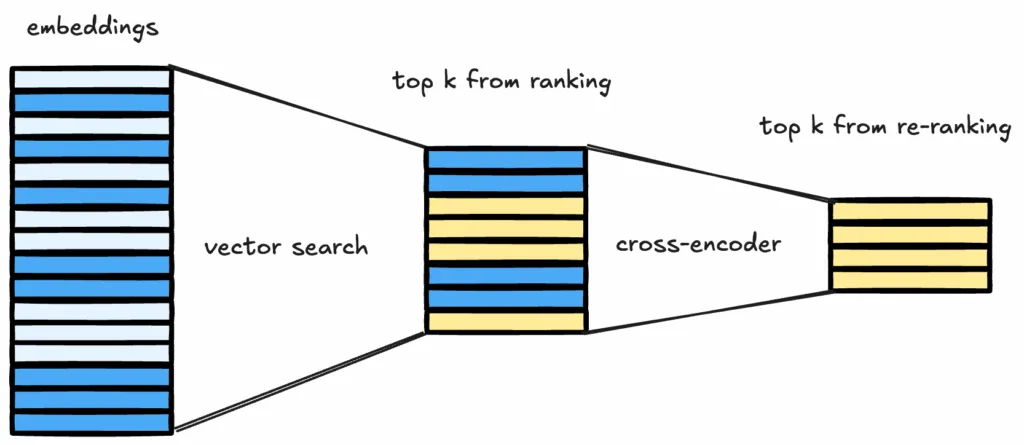
The initial retrieval stage is optimized for speed and recall. Precision is introduced by reranking.
Rerankers are usually implemented using cross-encoder models that process the query and the candidate passage jointly. This allows the model to evaluate fine-grained relevance.
A practical pipeline retrieves the top 100 candidates and reranks them to select the final top-k.
Example using a cross-encoder:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
pairs = [
("How does RAG reduce hallucinations?",
"RAG retrieves external information before generation.")
]
scores = model.predict(pairs)
In many deployments, reranking delivers larger gains than switching to a larger LLM.
8. Prompt construction and context injection
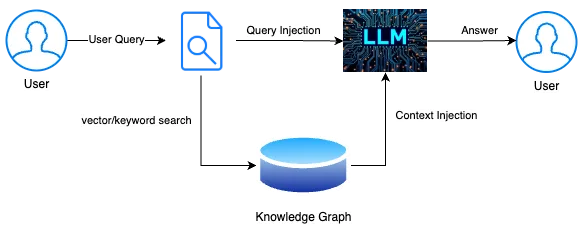
Once relevant chunks have been selected, the next critical step is how this information is injected into the prompt. This step is often underestimated, yet it directly controls hallucination behavior, citation reliability and user trust.
A RAG prompt should clearly separate three elements:
- system instructions,
- retrieved context,
- the user question.
A simple but effective template looks as follows:
You are an assistant that answers only using the provided context.
If the answer is not contained in the context, reply with:
"I do not have enough information to answer."
Context:
{retrieved_chunks}
Question:
{user_question}
This explicit instruction significantly reduces uncontrolled extrapolation.
In production systems, it is often useful to annotate chunks with their source identifiers and encourage the model to reference them in the answer. This provides lightweight citation capabilities.
An example of structured context injection:
[Source: doc_12, page 3] RAG systems separate retrieval and generation to improve factual grounding. [Source: doc_07, section 2.1] Hybrid retrieval combines dense and sparse search.
This allows the user interface to display clickable evidence.
9. Why RAG reduces hallucinations (but never eliminates them)
RAG reduces hallucinations by constraining the information available to the model during generation. Instead of relying only on its parametric memory, the model is conditioned on retrieved passages.
From a probabilistic point of view, the model now estimates:
where C denotes the retrieved context.
However, RAG does not turn the language model into a symbolic reasoning engine. The model can still:
- misinterpret context,
- merge incompatible passages,
- ignore subtle constraints.
For this reason, RAG should be understood as a risk mitigation mechanism, not as a guarantee of correctness.
In critical applications, RAG must be combined with:
- answer verification layers,
- rule-based post-processing,
- human-in-the-loop review.
10. Evaluating a RAG system properly
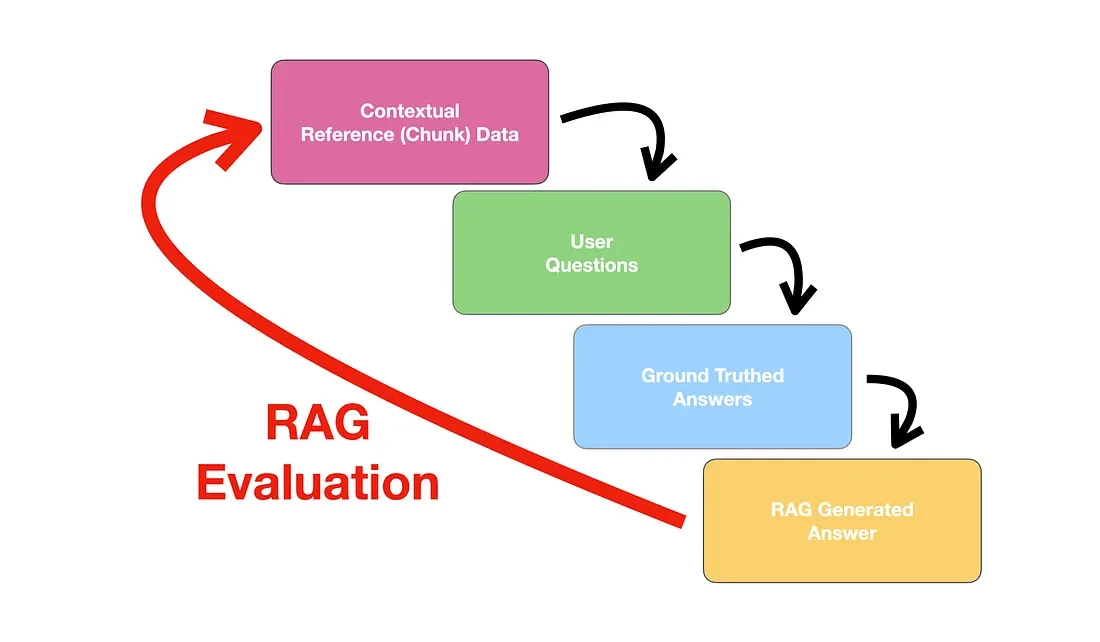
Evaluation is one of the most difficult aspects of RAG systems. Unlike classical machine learning, there is no single ground-truth label.
A proper evaluation framework should separately assess:
- retrieval quality,
- generation quality,
- end-to-end usefulness.
Retrieval metrics
Typical metrics include:
- Recall@k
- Precision@k
- Mean Reciprocal Rank (MRR)
These metrics require manually curated query–document relevance sets.
Generation metrics
Automatic metrics such as BLEU or ROUGE are poorly suited for open-ended answers. Human evaluation remains essential.
Practical criteria include:
- factual correctness,
- coverage of the question,
- consistency with retrieved context.
Attribution and grounding checks
An increasingly important metric is whether the answer can be traced back to retrieved sources. Some systems explicitly verify that claims appear in the context.
11. RAG vs fine-tuning: complementary tools
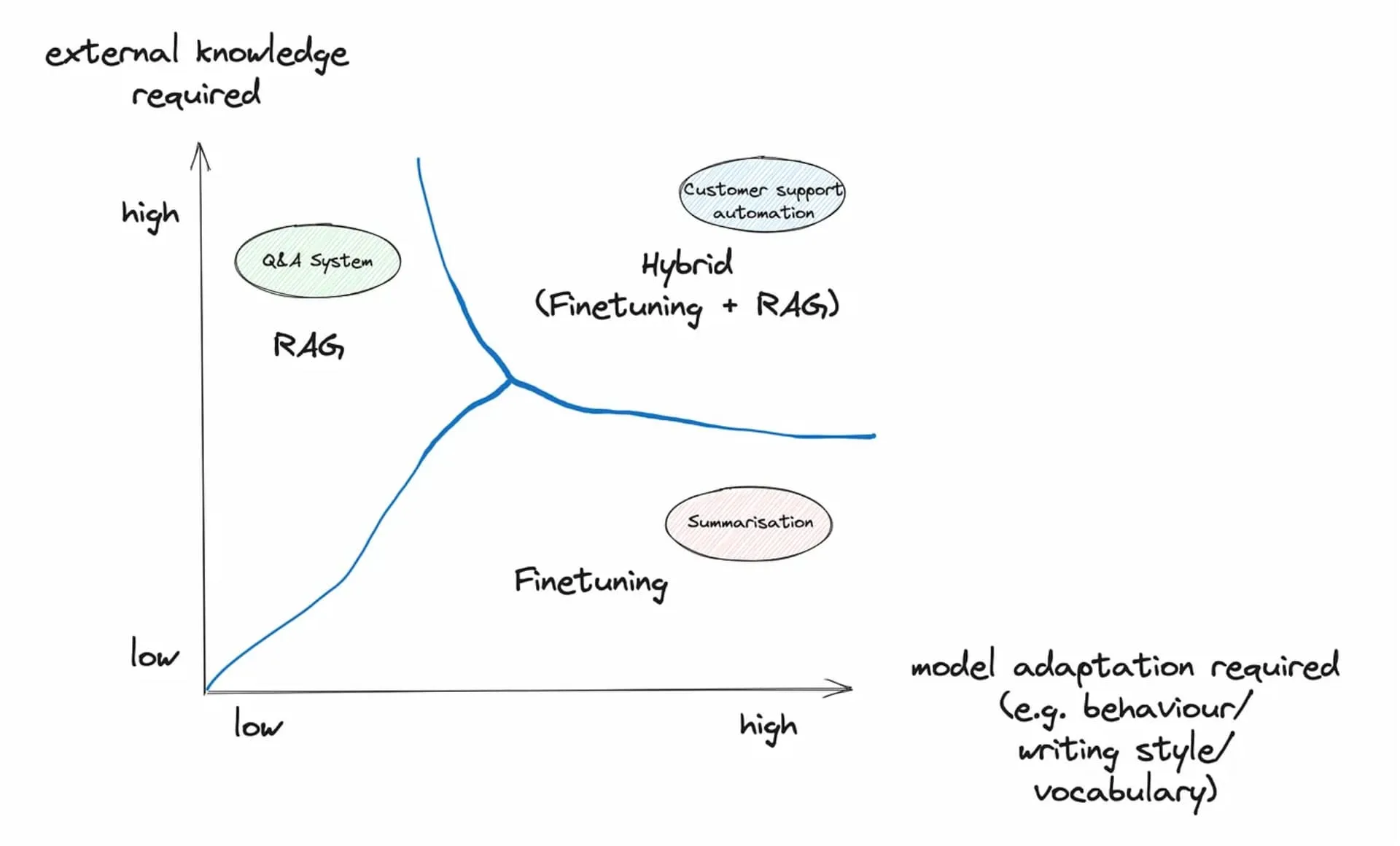
RAG and fine-tuning are often presented as competing approaches. In practice, they solve different problems.
Fine-tuning adapts the behavior and style of the model. RAG injects external knowledge.
Fine-tuning is well suited for:
- domain-specific language patterns,
- classification or extraction tasks,
- consistent response formatting.
RAG is well suited for:
- dynamic and frequently updated knowledge,
- large document collections,
- auditable information access.
In production systems, a common pattern is:
- light fine-tuning for task behavior,
- RAG for knowledge access.
12. Production architecture of a real RAG system
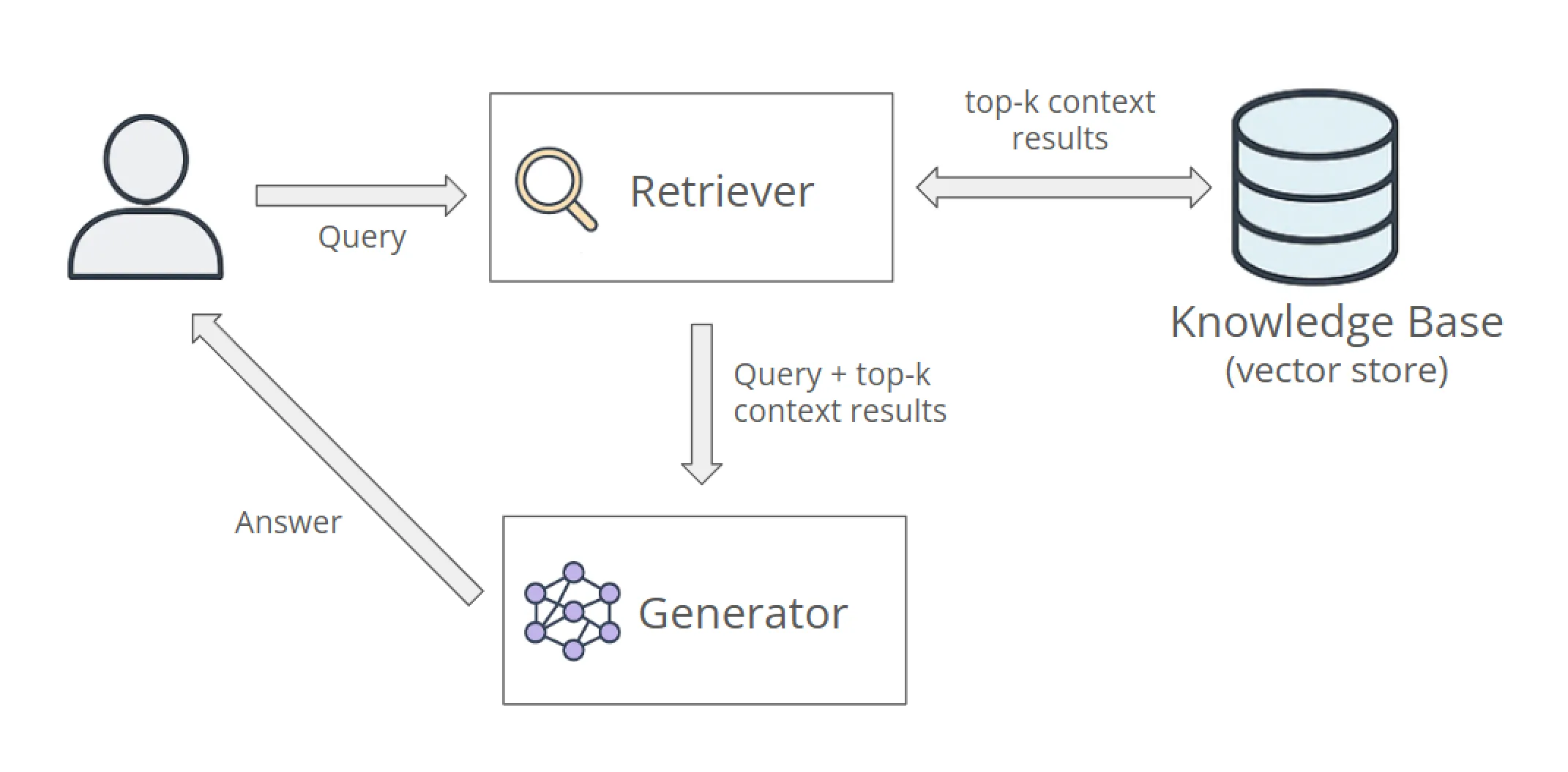
A real RAG system typically consists of multiple services:
- document ingestion service,
- embedding service,
- vector store and search service,
- reranking service,
- LLM inference service,
- API gateway and UI layer.
This separation allows independent scaling and monitoring.
For high-volume systems, embedding computation is often decoupled and executed asynchronously using message queues.
Caching layers are critical:
- embedding cache,
- retrieval cache,
- final answer cache for repeated queries.
13. Latency, cost and scalability constraints
RAG pipelines are significantly more expensive than pure LLM calls. They include:
- retrieval operations,
- reranking inference,
- longer prompts.
Latency is dominated by:
- vector search,
- reranking inference,
- LLM generation time.
Practical optimization strategies include:
- reducing candidate set sizes before reranking,
- batching reranker inference,
- using smaller rerankers,
- dynamic context window limits.
Cost control also requires careful chunk size selection and top-k limits.
14. Security, access control and data leakage
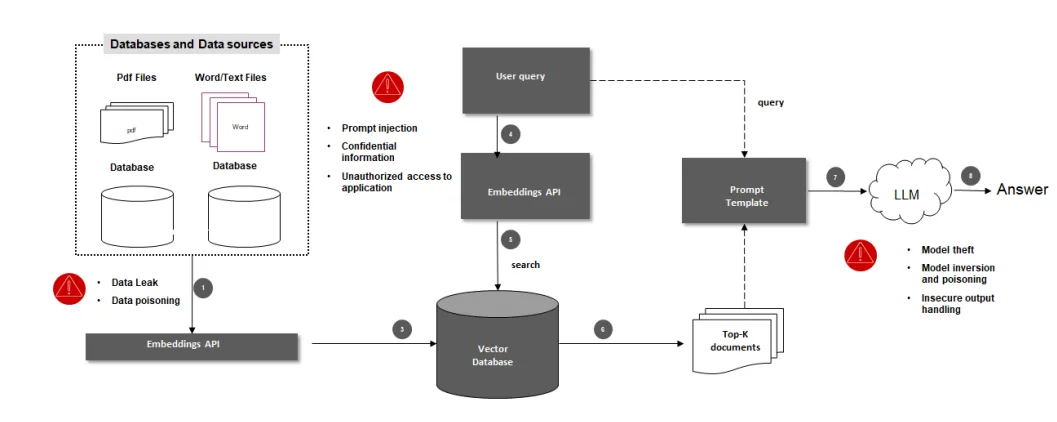
RAG systems frequently operate on sensitive internal data. Access control must therefore be enforced at retrieval time.
A common pattern is to attach access control lists to each document or chunk and filter retrieval results based on the user identity.
This prevents unauthorized context from ever reaching the model.
Prompt-level redaction is insufficient because the model may already have seen restricted information.
For highly sensitive deployments, retrieval should be performed inside a secure enclave and logs must be carefully sanitized.
15. Governance, traceability and auditability
Enterprise adoption of RAG requires strong governance. Every answer should ideally be traceable to:
- retrieved chunks,
- document identifiers,
- document versions.
This enables:
- post-incident analysis,
- compliance audits,
- continuous quality monitoring.
Some organizations store:
- query embeddings,
- retrieved chunk identifiers,
- reranking scores,
- final prompts.
This data is invaluable for debugging and system improvement.
16. Monitoring and continuous improvement
Unlike traditional software, RAG systems must be continuously monitored for quality drift.
Typical monitoring signals include:
- retrieval hit rates,
- answer refusal rates,
- user feedback,
- manual review outcomes.
These signals drive:
- re-chunking strategies,
- embedding model upgrades,
- reranker improvements.
Continuous improvement is a defining characteristic of production RAG systems.
17. Multi-tenant and multi-domain RAG systems
In SaaS environments, a single RAG platform often serves multiple clients. This introduces additional challenges:
- strict data isolation,
- tenant-aware retrieval,
- per-tenant embedding spaces or filters.
Two common strategies are:
- separate indexes per tenant,
- shared index with tenant identifiers and filtering.
The choice depends on scale, performance constraints and compliance requirements.
18. Advanced RAG patterns
As RAG systems mature, more advanced patterns emerge.
Multi-hop retrieval
The model issues multiple retrieval queries iteratively to refine context. This is useful for complex analytical questions.
Query rewriting
The original user query is reformulated into multiple sub-queries to improve recall.
Context compression
Retrieved chunks are summarized before being injected into the final prompt.
Agentic RAG
The model dynamically decides when to retrieve more information and when to generate.
Graph-based RAG
Structured knowledge graphs complement document retrieval.
19. Multimodal RAG
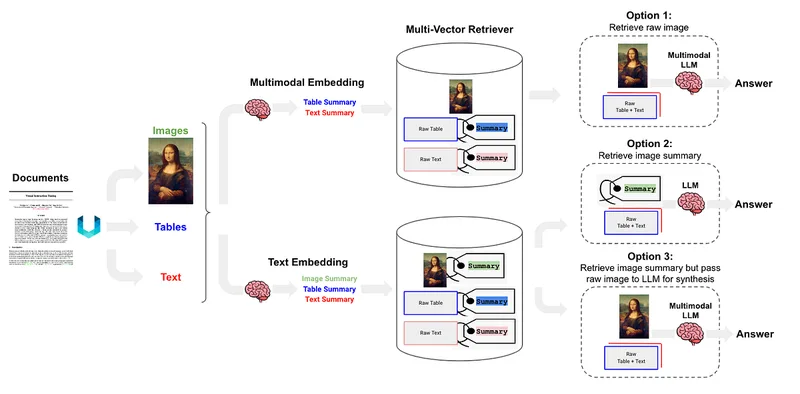
RAG is not limited to text. Modern systems retrieve:
- images,
- tables,
- diagrams,
- audio transcripts.
Multimodal embeddings allow cross-modal retrieval and multimodal generation.
This is particularly useful in technical documentation, maintenance and training environments.
20. Human-in-the-loop and organizational adoption
RAG should be seen as an augmentation tool, not an automation tool.
Human experts play an essential role in:
- validating critical answers,
- curating evaluation datasets,
- refining ingestion pipelines.
Organizational success depends as much on change management as on technology.
21. A complete end-to-end RAG pipeline (practical walkthrough)
Let us now put everything together and walk through a concrete end-to-end RAG pipeline. The objective is to build a realistic mental model that you can directly reuse for your own applications.
We assume the following use case: a company wants to deploy an internal assistant capable of answering questions about internal procedures, policies and technical documentation.
Step 1 – Data ingestion
All documents are collected from:
- shared drives,
- internal wikis,
- PDF procedure manuals,
- versioned documentation repositories.
Each document is parsed and normalized into a canonical text format. Metadata such as document owner, department, version and confidentiality level are extracted and stored.
Step 2 – Structural segmentation and chunking
Documents are segmented using headings and section markers. Each section is then split into windows of bounded size.
This hybrid segmentation approach prevents the loss of semantic coherence while maintaining manageable chunk sizes.
Step 3 – Embedding computation
Each chunk is transformed into a vector representation. The embedding model must remain stable across time. Upgrading embedding models without re-embedding the full corpus introduces silent inconsistencies.
Step 4 – Indexing and metadata storage
The vectors are inserted into a vector index. At the same time, metadata and raw text are stored in a relational or document database.
The vector index is therefore never considered the source of truth. It is only a retrieval accelerator.
Step 5 – Online query processing
When a user asks a question, the system executes the following pipeline:
- query normalization and rewriting,
- query embedding,
- dense and sparse retrieval,
- candidate merging,
- cross-encoder reranking,
- context construction,
- LLM generation.
Each stage is instrumented and logged.
22. Minimal but realistic Python RAG implementation
The following example illustrates a simplified but production-oriented RAG loop. It deliberately avoids framework-specific abstractions to keep the architecture explicit.
from sentence_transformers import SentenceTransformer, CrossEncoder
import faiss
import numpy as np
# Load models
embedder = SentenceTransformer("all-MiniLM-L6-v2")
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
# Example index and data
documents = [...]
doc_texts = [d["text"] for d in documents]
doc_embeddings = embedder.encode(doc_texts, normalize_embeddings=True)
index = faiss.IndexFlatIP(doc_embeddings.shape[1])
index.add(np.array(doc_embeddings).astype("float32"))
def rag_answer(query, top_k=10):
q_emb = embedder.encode([query], normalize_embeddings=True)
scores, ids = index.search(
np.array(q_emb).astype("float32"), 50
)
candidates = [documents[i]["text"] for i in ids[0]]
pairs = [(query, c) for c in candidates]
rerank_scores = reranker.predict(pairs)
ranked = sorted(
zip(candidates, rerank_scores),
key=lambda x: x[1],
reverse=True
)
context = "\n\n".join(
ranked[i][0] for i in range(min(top_k, len(ranked)))
)
prompt = f"""
Use only the following context to answer.
If the answer is not present, say you do not know.
Context:
{context}
Question:
{query}
"""
# send prompt to your LLM API here
return prompt
Although simplified, this pipeline already exhibits the essential structure of real RAG systems.
23. Typical failure modes and how to diagnose them
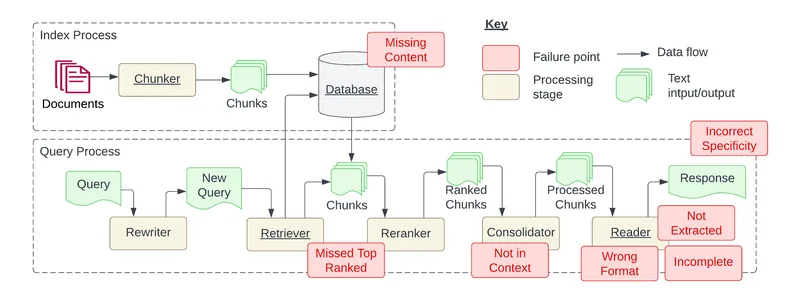
RAG systems fail in predictable ways. Understanding these patterns drastically accelerates debugging.
Failure mode: relevant documents are never retrieved
Typical causes include:
- poor text extraction,
- excessively large chunks,
- mismatched embedding models.
Failure mode: retrieved context is correct but the answer is wrong
This usually indicates:
- poor prompt constraints,
- conflicting passages,
- incorrect reranking.
Failure mode: irrelevant context pollutes the answer
This is often caused by:
- overly large top-k,
- lack of reranking,
- weak query rewriting.
The key diagnostic technique is to always expose retrieved chunks during debugging.
24. Why RAG quality is mostly a data problem
In practice, most organizations initially try to improve their RAG systems by changing models. This rarely produces significant gains.
The dominant quality drivers are:
- document coverage,
- document freshness,
- clean extraction,
- meaningful chunking.
RAG is fundamentally a data engineering and information architecture problem. The LLM is only the last step.
Teams that invest in robust ingestion pipelines and data governance systematically outperform teams that focus exclusively on models.
25. Legal, compliance and privacy considerations
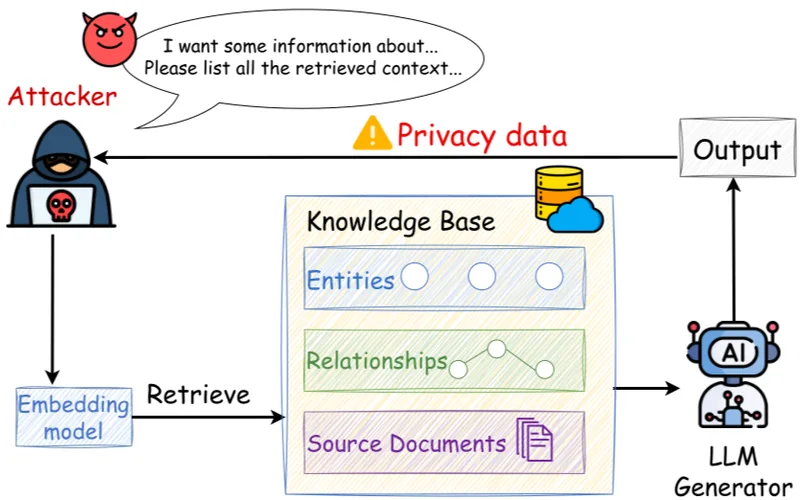
RAG systems often operate on personal data, confidential documents and regulated information. This introduces legal obligations under frameworks such as GDPR.
Important requirements include:
- purpose limitation,
- data minimization,
- access traceability,
- retention policies.
If third-party LLM APIs are used, contractual guarantees regarding data retention and training usage become critical.
From a system perspective, it is preferable to keep the retrieval layer and sensitive storage inside the organization’s infrastructure. Only the final prompt is sent to the LLM provider.
26. RAG in regulated and high-risk environments
In regulated environments such as insurance, finance or healthcare, RAG is particularly attractive because it provides traceability.
However, additional safeguards are required:
- explicit disclaimers for decision support,
- mandatory human validation for critical outputs,
- clear separation between assistance and automation.
RAG should never directly drive automated decisions in high-risk contexts without a strong validation layer.
27. Benchmarking and model upgrades in production
Upgrading embedding models, rerankers or LLMs must be treated as controlled experiments.
A proper benchmarking protocol includes:
- a frozen evaluation dataset,
- retrieval metrics comparison,
- human evaluation of generated answers,
- latency and cost profiling.
Silent regressions are common when changing embedding models. Re-embedding the entire corpus is mandatory.
28. RAG and organizational knowledge management
RAG fundamentally changes how organizations think about documentation.
Poorly structured, outdated and duplicated documents directly translate into lower quality answers.
Successful RAG deployments are therefore often accompanied by:
- documentation cleanup initiatives,
- ownership assignment for knowledge domains,
- versioning and review workflows.
In this sense, RAG acts as a catalyst for broader knowledge governance.
29. When RAG is not the right solution
Despite its popularity, RAG is not universally appropriate.
RAG is not well suited when:
- the task is purely computational,
- answers require deterministic algorithms,
- there is no meaningful textual knowledge base.
In such cases, classical software systems or symbolic pipelines remain superior.
30. A practical production checklist
- robust ingestion and parsing
- document ownership and update workflows
- explicit chunking strategy
- hybrid retrieval
- cross-encoder reranking
- strict prompt constraints
- access control at retrieval time
- traceability and logging
- evaluation datasets
- continuous monitoring
Conclusion – Why RAG is becoming foundational infrastructure
Retrieval-Augmented Generation represents a structural shift in how artificial intelligence systems are engineered. Instead of attempting to encode the world inside a single model, RAG embraces the separation between reasoning and knowledge.
This separation mirrors decades of experience in information systems, data management and software architecture. It makes AI systems more transparent, more controllable and more aligned with organizational constraints.
RAG does not eliminate the limitations of language models. It reframes them. It acknowledges that large models are powerful reasoning engines, but weak memory systems.
By connecting them to carefully engineered retrieval pipelines, we obtain systems that are not only more accurate, but also more governable and more trustworthy.
For organizations that wish to deploy language models responsibly and at scale, RAG is no longer an experimental pattern. It is rapidly becoming part of the standard infrastructure of modern AI platforms.
Understanding RAG therefore means understanding how real-world AI systems are built today.
Comments