
DeepSeek R1: A New Era of Reasoning-Centric Large Language Models
Large
language models (LLMs) are transforming AI.
DeepSeek R1 is an open-source model that emphasizes reasoning.
It rivals closed models such as GPT-4 and Llama.
Introduced in January 2025, DeepSeek R1 builds on previous systems like DeepSeek-V3. Its efficient design offers comparable performance to top-tier systems at a lower cost. This article explores its architecture, training pipeline, and diverse applications.
What made DeepSeek R1's release extraordinary was not just its benchmark scores - it was the cost. DeepSeek's team reported training the underlying DeepSeek-V3 model on approximately 2,048 NVIDIA H800 GPUs for 55 days, at an estimated cost of just $5.6 million. For context, models of comparable capability from OpenAI or Google are believed to cost hundreds of millions of dollars to train. This revelation sent shockwaves through the technology industry: on January 27, 2025, NVIDIA's stock dropped 17% in a single session - erasing roughly $600 billion in market capitalization - as investors questioned the long-held assumption that leading AI required ever-larger, ever-more-expensive GPU clusters.
The geopolitical dimension adds further complexity. DeepSeek is a product of a Chinese AI lab, and it achieved frontier performance despite US export controls that restrict access to the most advanced chips (H100, A100). This demonstrated that hardware constraints do not necessarily translate into capability constraints - a finding that sparked intense debate in AI policy circles about the effectiveness of technology export restrictions. For the broader AI community, DeepSeek R1 reinforced a key lesson: algorithmic innovation and training efficiency can, under the right conditions, rival raw compute.
1. Technical Architecture
DeepSeek R1 is based on the Transformer architecture. It tokenizes text into subword units and converts them into embeddings. Multiple self-attention layers capture both local and global dependencies.
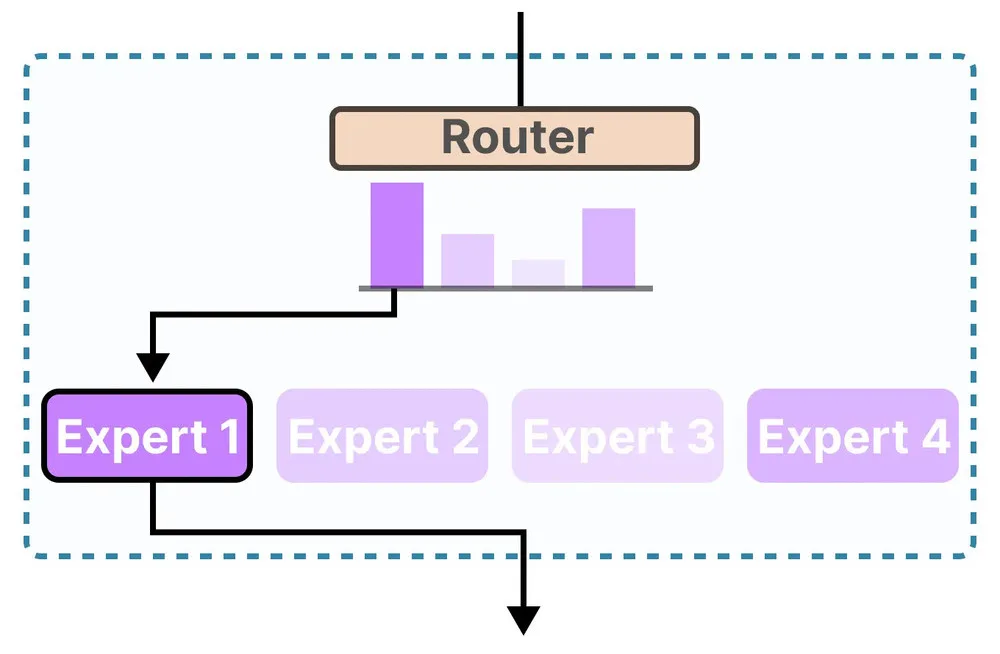
A key innovation is the Mixture-of-Experts (MoE) design. With a total of 671 billion parameters, only about 37 billion are active per token, thanks to a dynamic routing system.
This dynamic routing enables expert specialization. For example, one group of experts may focus on code, while others excel in math.
The core self-attention operation is defined as:
Here, Query (Q), Key (K), and Value (V) matrices are derived from the input embeddings.
Advanced positional encoding strategies (e.g. rotary embeddings) support its extended context of up to 128K tokens. This is a major leap over models like GPT-4 or Llama 2.
Additionally, the backbone supports a chain-of-thought output.
The model displays reasoning steps within <think> tags, enhancing transparency.
2. Training Methodology
DeepSeek R1 was trained using a multi-stage pipeline that goes beyond the traditional pretrain–fine-tune model.
- Base Pre-training: The model was pre-trained on about 14.8 trillion tokens using FP8 mixed precision for efficiency. This phase used roughly 2.788 million GPU-hours on NVIDIA H800-class hardware.
- Reinforcement Learning Phase 1 (R1-Zero): The model was directly optimized using a rule-based reward system. It was rewarded for both correct answers and for producing a detailed chain-of-thought output.
- Supervised Fine-Tuning (SFT): Curated examples were used to refine the model’s style, ensuring clarity and language consistency.
- Reinforcement Learning Phase 2 (Alignment): Additional rewards emphasized concise, helpful responses while keeping the chain-of-thought intact.
- Model Distillation: The full 671B MoE model was compressed into smaller variants (7B, 14B, 32B) for broader accessibility.
GRPO: Group Relative Policy Optimization
The reinforcement learning stages rely on a training algorithm called Group Relative Policy Optimization (GRPO), introduced alongside DeepSeek R1. Unlike standard Proximal Policy Optimization (PPO), which requires a separate critic model to estimate the baseline value of a state, GRPO estimates the baseline from the group of candidate outputs itself.
For each question, the model generates a group of G candidate responses. The reward for each response is compared to the average reward across the group. Responses that score above average receive positive reinforcement; those below average are penalized. This self-referential comparison eliminates the need for a separate value network - cutting both memory usage and training complexity roughly in half. The result is a leaner, more stable RL training loop that scales more efficiently to large models.
A key design choice was using rule-based rewards rather than a learned reward model. Mathematical problems have verifiable answers (correct or not), and code can be executed against test cases. These binary signals are cheap to compute and immune to the "reward hacking" that often plagues human-preference reward models. The combination of GRPO with verifiable rewards is what allowed DeepSeek R1 to develop strong, consistent reasoning behavior without requiring vast amounts of human annotation.
Ethical considerations and bias mitigation were integral to the training. Although the model inherits biases from its training data, its open-source nature enables community oversight.
3. Applications and Use Cases
DeepSeek R1’s advanced reasoning and long-context capabilities unlock many applications:
- Complex Problem Solving: The model breaks down challenging math and logic problems into clear, digestible steps. For instance, it can tutor students by explaining calculus or proving theorems.
- Code Generation and Debugging: With an Elo rating of over 2000 on platforms like Codeforces, it excels in generating, reviewing, and optimizing code.
- Knowledge Assistance: Its extended context (up to 128K tokens) enables it to summarize legal documents, scientific papers, and enterprise reports.
- Creative Writing: DeepSeek R1 can generate engaging content and explain its reasoning, making it a valuable tool for writers and marketers.
- Long-Context Analysis: It can sift through contracts or meeting transcripts to deliver targeted insights.
- Research and Development: The model’s detailed chain-of-thought outputs are used to generate training data for specialized, smaller models.
Enterprises are exploring its integration into customer support systems and financial analysis tools to provide transparent, data-driven insights.
This video provides an overview of DeepSeek R1’s innovative architecture and real-world applications.
4. Code Implementation
The snippet below demonstrates how to load a distilled version of DeepSeek R1 using the Transformers library.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load DeepSeek-R1 Distilled (Qwen-7B variant)
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Define a complex question with a chain-of-thought prompt
question = "Q: What is the sum of the first 10 prime numbers? Let's think step by step.\nA:"
inputs = tokenizer(question, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=False, temperature=0.0)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
The output may include a detailed chain-of-thought trace, for example:
This transparency helps verify the final answer and aids in debugging.
Another example is using DeepSeek R1 for code generation. Consider this prompt for a Python function to check if a number is prime:
# A prompt for code generation
code_prompt = "Q: Write a Python function to check if a number is prime.\nA:"
inputs = tokenizer(code_prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200, temperature=0.2)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
The model may output code along with its reasoning, enhancing clarity and trust.
5. Challenges and Limitations
Despite its advanced capabilities, DeepSeek R1 faces several challenges:
- Resource Intensity: With 671B parameters (37B active per token), it requires significant computing power. Even with MoE reducing per-token costs, real-time deployment needs high-end infrastructure.
- Complexity of MoE: The dynamic routing adds challenges in fine-tuning and deployment. Balancing expert usage often requires custom engineering solutions.
- Emergent Behaviors: The reinforcement learning approach may cause overly verbose outputs. While the chain-of-thought is valuable, in casual use users might prefer concise answers.
- Knowledge Cutoff: Its training data is current up to around 2024. In rapidly changing fields, this can result in outdated or incorrect information.
- Bias and Ethics: The model inherits biases from its training data. Ongoing monitoring and community oversight are essential to mitigate potential issues.
- Long-Context Challenges: Handling up to 128K tokens is innovative, but extended contexts can slow processing and dilute focus if too much text is provided.
- Evaluation and Trust: Benchmark scores are strong, but real-world performance may vary, particularly in nuanced or commonsense reasoning tasks.
These challenges emphasize the need for continuous research and iterative improvements. Future iterations (e.g., DeepSeek R2) are expected to address these limitations.
6. Industry Impact and Future Directions
DeepSeek R1 marks a turning point for both research and industry. Its open-source nature and state-of-the-art reasoning capabilities promote collaboration and innovation.
Enterprises in finance, healthcare, and customer support are already exploring its integration. Its ability to process long documents enables in-depth report analysis, risk assessment, and enhanced decision-making.
Looking ahead, multi-modal models that combine text with images or audio are on the horizon. Researchers are exploring how to integrate external tools (e.g., calculators or databases) directly into the reasoning process.
The community-driven development model ensures continuous feedback, and distilled variants make the technology accessible to organizations with limited resources. Experts predict these models will soon be standard in fields requiring transparent reasoning.
Future research aims to further compress models without sacrificing performance, improve the interpretability of chain-of-thought outputs, and develop robust safety protocols.
7. Benchmark Performance
DeepSeek R1 was evaluated on the same benchmarks used to assess leading proprietary models. The results were remarkable for an open-source system, particularly on mathematics and coding tasks that demand multi-step reasoning.
| Benchmark | What it measures | DeepSeek R1 | OpenAI o1 | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|---|---|
| AIME 2024 | Olympiad-level mathematics | 79.8% | 74.4% | 9.3% | 16.0% |
| MATH-500 | Competition math | 97.3% | 96.4% | 76.6% | 78.3% |
| LiveCodeBench | Real-world coding problems | 65.9% | 63.4% | 34.2% | 40.8% |
| MMLU | Broad academic knowledge | 90.8% | 91.8% | 87.2% | 88.7% |
| GPQA Diamond | Graduate-level science Q&A | 71.5% | 75.7% | 53.6% | 65.0% |
Source: DeepSeek R1 Technical Report (arXiv:2501.12948). Green = best score in row.
On mathematics (AIME 2024, MATH-500), DeepSeek R1 slightly surpasses OpenAI o1. On general knowledge (MMLU, GPQA), it is neck-and-neck. The gap is widest on tasks where GPT-4o was not purpose-built for reasoning - math and competitive coding - which is precisely where DeepSeek R1's GRPO-based training shines.
The distilled variants are equally noteworthy. DeepSeek-R1-Distill-Qwen-7B - a 7-billion-parameter model - scores higher on AIME 2024 than GPT-4o, a model estimated to be 10–20x larger. This is arguably the most striking result in the paper: reasoning ability can be transferred to small models through distillation far more effectively than previously demonstrated.
8. Conclusion
DeepSeek R1 is a monumental achievement in large language models. By combining a powerful Mixture-of-Experts architecture with innovative reinforcement learning techniques, it achieves advanced reasoning and problem-solving capabilities that were once limited to proprietary systems.
Its design emphasizes transparency through chain-of-thought outputs, allowing users to see not only the final answers but also the reasoning behind them.
This article has examined DeepSeek R1’s technical architecture, multi-stage training pipeline, diverse applications, and the challenges it faces. It also discussed the significant industry impact and future directions for reasoning-centric AI.
As research continues and community contributions drive further improvements, AI systems will not only solve complex problems but also explain their reasoning in a human-like manner. This transparency is essential for building trust and ensuring responsible deployment.
In conclusion, DeepSeek R1 is not just another large language model - it is a comprehensive platform for reasoning-centric AI that sets a new benchmark in the field and offers a glimpse into the future of autonomous, explainable AI.
For further reading and technical details, please consult:
- DeepSeek R1 Technical Report
- Mixture-of-Experts in Language Models
- Attention is All You Need
- Reinforcement Learning
This comprehensive article has provided an in-depth look into DeepSeek R1’s innovations, applications, challenges, and future directions - marking a new era in reasoning-centric AI.
Comments